
You Need A Theory of Victory
The cause of AI safety is losing. Consider asking: how can we win?

Note: The majority of this post is adapted from a talk I gave recently. These do not represent the views of my employer.
Scroll around the organizations on this cute AI safety map. Think about, or ask, how does their work help with AI safety?
My guess is that, maybe some won’t know, but most would say “X of our actions will lead to Y self-evidently good outcome.”
Maybe, they’ll say, if we measure model capabilities well (we have the graph), policymakers will wake up and see AIs are improving quickly, and get their act together. In the best case, we could become a neutral third-party evaluator, and we could tell the labs that they can’t release the next model because our autonomy & deception evals say it’s too dangerous. Better information leads to better decision-making. You couldn’t be against that.
Maybe, if we invent the scaffolds for the right AI monitors (AIs looking at the output of other AIs), we could coax interesting work out of near-AGI systems that we don’t trust to help automate alignment. In the best case, these millions of automated AI alignment researchers, at the brink of AGI, solve the problem. You couldn’t be against that.
Maybe, at least publicly, there is no unifying thread to our work. We do things that are the obvious low hanging fruit, again and again and again, and that’s how we contribute value. Maybe we help whistleblowers, or potentially-sentient AIs, or research mentors with good taste. Maybe we ask unusual philosophical questions. Maybe we meld into the national security establishment, or the government. Maybe we organize a movement of people. Maybe we just say the truth. Surely, you couldn’t be against that.
Perhaps you can see the holes in some of these arguments, or actions. But “generically good thing” isn’t enough! Take that thread, ask the question: how do these actions, in concert with others, lead to us “winning?” I would argue, however, that very few of the actions or organizations have a theory of victory -- a full (causal) story of the steps that need to go right, and a plan to achieve them. Very few begin to ask.
In April, I gave a talk at an AI policy workshop about these theories of victory, and how to develop your own. The rest of this post is an annotated and lightly edited version of the talk below. It’s a long one.
Overview
The main claim, up top:

We’ll quickly preview:

What is “Victory”?
There are many different potential threat models in AI.

Many people in many different organizations care about many different things, but perhaps two that we can agree on are:

Perhaps there is a more specific vision of what a good future might look like, perhaps some form of Utopia (like Forethought’s Viatopia or Nozick’s “Utopia of Utopias” and Alexander Wales’ lovely fictionalization of it), but for this talk we’ll stick to the broadly agreeable things.

Theories of Victory (ToVs)
To achieve a good outcome, people normally advocate for “theories of change”, which tend to take the form: “here’s my best guess for a causal chain for my action X causes Y.” X is a well-defined action (start an organization, run this media campaign etc.), and Y is a broadly-accepted “good thing” (“increases awareness of AI risks” “increases the probability of rational decision-making”)

This is, however, importantly distinct from a “Theory of Victory”, which I would understand as the full (causal) story of the steps that need to go right for us to “win” (where, borrowing the broadly-agreeable understanding of “win” from earlier -- we don’t die + the benefits of AI are broadly distributed.)
There’s this great quote from HPMOR against complex, multi-step plans (cited originally in Scott Alexander’s brilliant book review of Zero to One). I disagree! Yes, indeed, they are fragile, but you should know the causal story of how all the actions are going to lead to the correct things happening.
So how’s this different from a Theory of Change? It accounts for
All of the actions of all the actors, the steps whether they are performed by you or not
The full win condition, rather than simply a “self-evidently good action.”

***
ToVs in AI Safety
The next section of the talk is a quick overview of the explicit and implicit (unsaid) assumptions underlying what I, and regular readers of this blog, would term the “two camps in AI safety.” I will say, they don’t often agree, and can have quite vicious disagreements indeed. (insert Freud here about the narcissism of small differences)
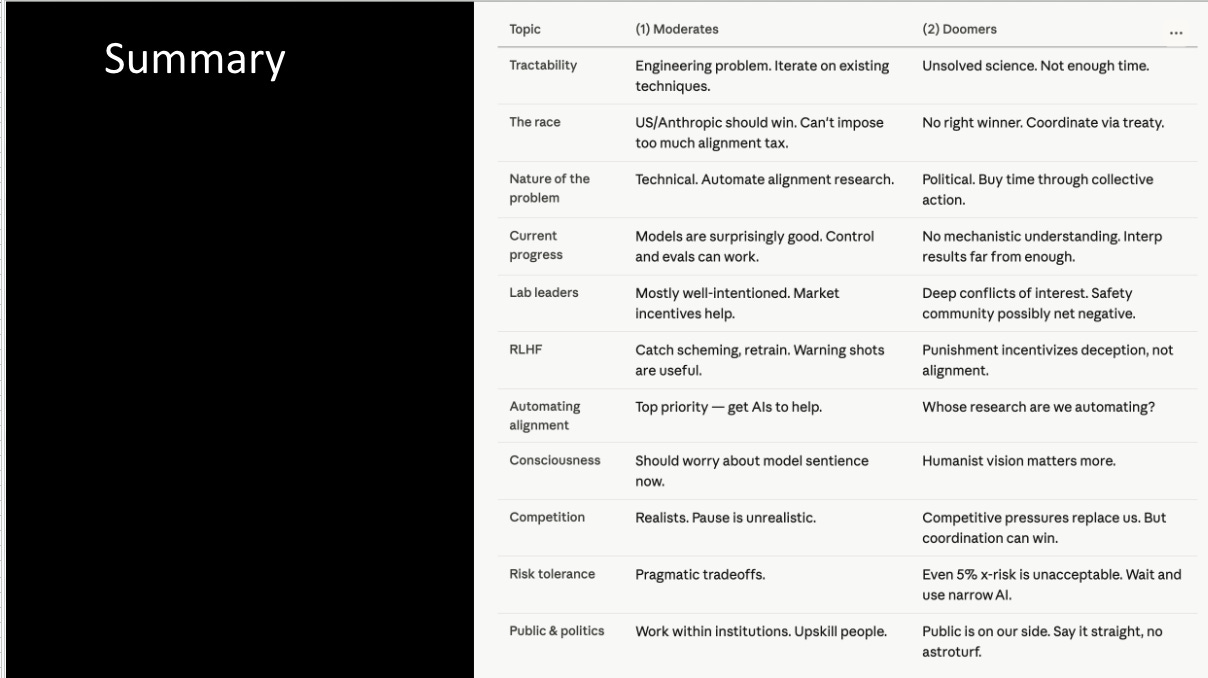
The camps are broadly the “alignment is hard but tractable” folks (“EAs” “moderates”) and the “if anyone builds it, everyone dies”) folks (or “doomers” “humanists”).
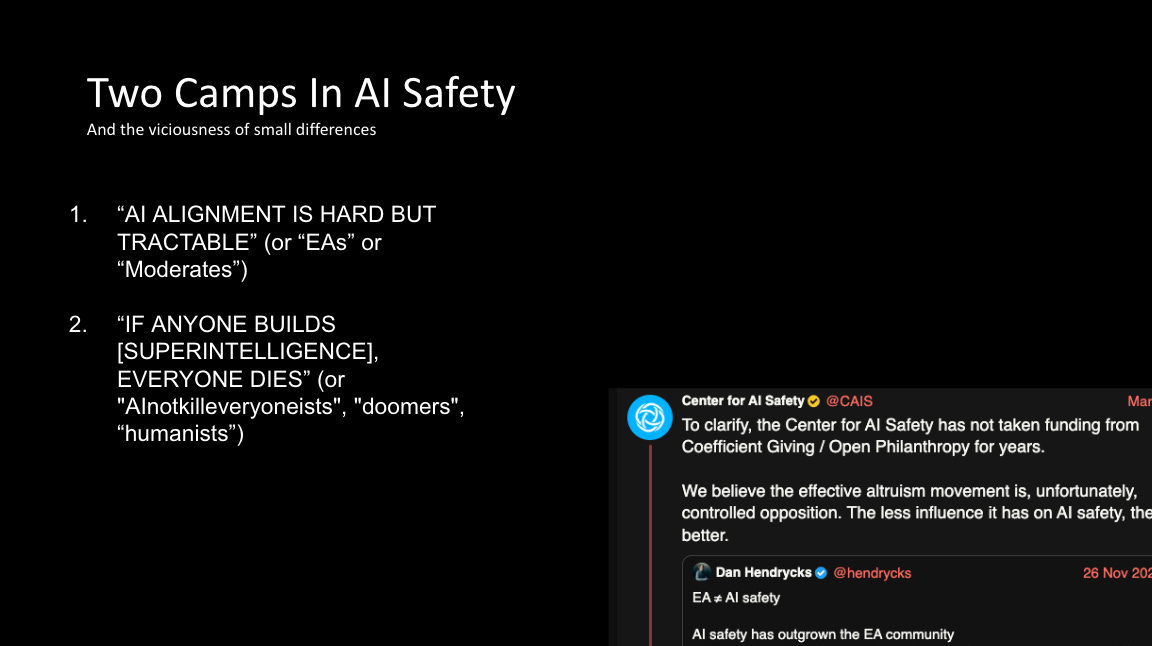
Camp 1
In Camp 1, we find the vast majority of funding and attention in AI safety. One can maybe summarize the specific solution prescribed by this camp as “the right people need to win the race” (so, the US, for democracy’s sake, and Anthropic, so that responsible labs are in the lead, and you can buy time at the frontier to do safety work). This position is perhaps best captured by Leopold’s Situational Awareness, which is worth reading in full (but in particular “The Free World Must Prevail”)

I’ll rapid-fire through a bunch of the explicit and implicit assumptions that underlie this worldview. The question of AI Alignment (getting AIs to do what we want), first and foremost, needs to be tractable: not to say that it is easy -- though some in this camp will claim that we got lucky with current systems -- but that it is an “engineering-shaped” problem, with continuous improvement possible from existing system, and would benefit from it being automated.
If you believe these systems are controllable, then the controller matters -- ideally it should be the best or most moral people (US/Anthropic), perhaps with some democratic input.

This view would look favorably upon the progress that has been made so far, favorably upon the lab leaders (or at least some), where market incentives don’t result in everyone dying, and that existing techniques perform surprisingly well.
Automating alignment is a top priority (getting AIs to help us do our homework) and, implicitly, the alignment problem is one that AI can help solve without itself being aligned first (the entire “getting work from untrusted systems” motivation behind much of the AI control agenda). This view is best written in Carlsmith’s “AI for AI safety” series, but also hinted at by Jan Leike’s “Alignment is not solved but it increasingly looks solvable.”

And finally, on “competitive pressures”, that a pause is unrealistic, and that the games and the incentives are fixed. Political action is harder to influence and has more backfire risk, that not building superintelligence ever is an economic and moral disaster, an existential risk of its own, and that the public should work within institutions, and build technocratic competence. Don’t, they say, activate forces that you can’t control.

I will, here, interject with my opinion. Perhaps best summarized by my post “whose alignment research are we automating”, and the general take of we should not rely on the benevolence of individuals (like lab leaders) for our good outcomes, no matter how similar to us they seem (particularly crazy given that those individuals are saying that the technology they are building may end the world), and that we should not rely on Kumbaya / rational decision-making / a warning shot to prevail for pausing right at the edge to do automated alignment research.
Camp 2
The second camp would, of course, advocate for a ban on superintelligence and, to achieve this, maybe a global treaty, because “if anyone builds it everyone dies.” FLI, for example, might advocate for a carve out of broad scientific and democratic consensus, but maybe not.

Again, going through the different explicit and implicit assumptions. AI alignment is an unsolved scientific problem, we have one critical try. Even if its only a 20% chance that we all die, why not do the more cautious thing, wait 5 years, and lower that further. This is everyone’s lives.
There is no correct winner in the race, it’s “if anyone builds it.” The only winner of a US-China race to superintelligence is the superintelligence itself. The problem is therefore a political one -- we need to buy time through collective action, and the bottleneck isn’t technocratic competence or “thoughtfulness”, it’s aligning political incentives. The AI safety progress we’ve made so far, some of it has been significant, but much is safetywashing that does not help with the hard problem.
I’d recommend reading Eliezer’s “list of lethalities”, the case against AI control research and Control AI’s plan, to get a flavor of what the views and actions of this crowd will be.

Yes, more, that lab leaders are rife with conflicts of interest, that the “AI safety” community has plausibly been net negative (with its $30m donation to OpenAI, its contribution to the funding and founding of Anthropic, the original inspiration of Deepmind). That RLHF, and RLHF++ and other existing alignment techniques will not be robust enough to prevent deception, particularly on hard to verify tasks, that we don’t know who’s research we are automating, and that sounds like a cop-out.
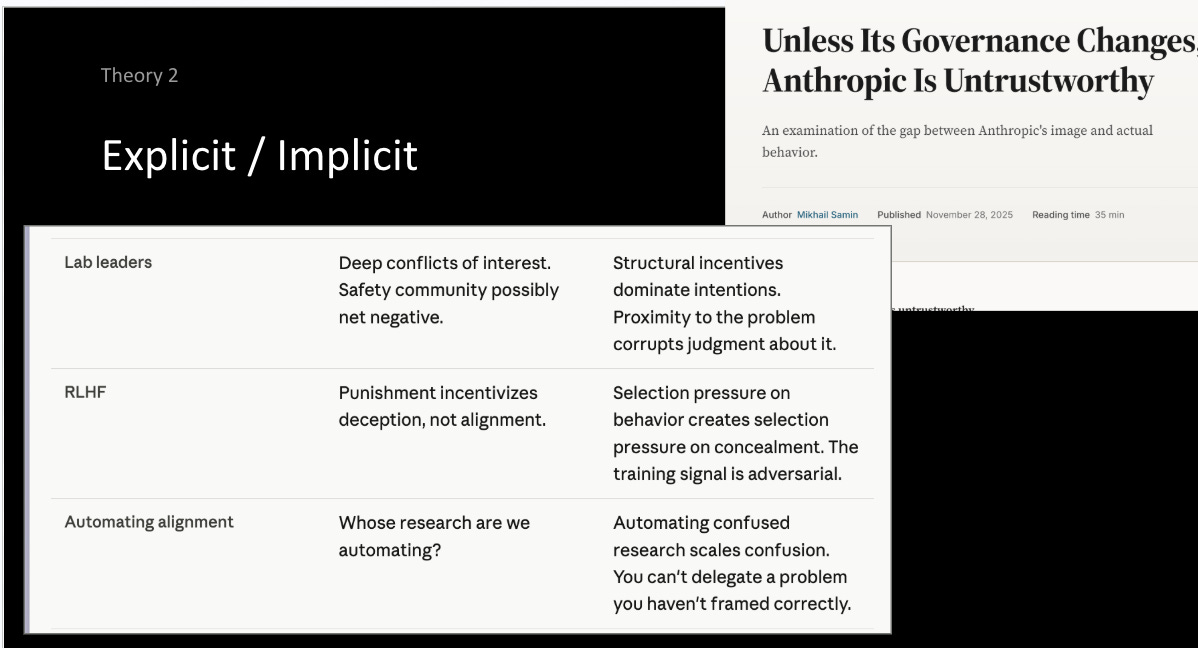
Perhaps the method here is that if you say the true things loudly, combined with a crisis, that persuasion will be enough if you’re right (huh, notice how that is a bit similar to the evidence-presenting pitch of the first crowd…)

I will, again, say that this theory of victory is not sufficient! My opinion: in some versions, this worldview relies on a warning shot being legible and not catastrophic, that people who are right, and right loudly, can persuade powerful people, that government can act fast enough, and that there exists a stable equilibrium where we can just stop -- I’m skeptical of all of these, or not confident enough to bet humanity on it.

A quick recap
Others
I will, of course, say there are many other theories of victory, and none of them are sufficient (and some of them just barely manage to scrape by as theories of victory at all -- many are fuzzy or implied on the full causal chain). I’ll tour through some others, briefly.
Def/acc + AI resilience. Let’s differentially boost defensive technologies like pandemic preparedness (Vitalik / OAI foundation / the smarter techno-optimists). Well, you better hope that the world favors defense over superintelligence, and I don’t think it does.
Liability + insurance mandates (the more pro-market of the worriers -- I like Gabe Weil). Just require the AI companies to get insurance against destroying the world, and the insurers will price it. Problem: If the stakes are the whole world, your insurance might be expensive -- insurers really don’t like insuring for highly correlated large events, like pandemics. Otherwise, if you make companies liable for near-misses too, good luck defining and detecting those, and similarly hoping that warning shots will happen.
State regulation (some of the AI safety c4s out there). Maybe the “patchwork” of state regulation may save us all. Problem: pre-emption. China. I’m not sure this counts as a full theory of victory, and I’m pretty sure the proponents would agree.
Coordination by Kumbaya. A strategy I like to think comes from the philosophical school of “people are rational actors, and they will update rationally in response to real evidence”, or, alternatively, hoping that Dario and Demis will get their 5 year pause by magic (I still love the Economist for forcing them together to sit uncomfortably close on that couch). Problem: people aren’t rational agents.
MAD-for-AI. As advocated best in “Superintelligence Strategy.” Maybe deterrence, or broader AI geopolitics, may find that equilibrium. Problem: convincing the US / China to preemptively cyber/physically escalate against another nuclear armed power is a really high bar, the government is slow. Cyber-hardening.
The market will solve it. (e/accs, a16z, some of the tech right) What’s the quote from the techno-optimist’s manifesto? “To ensure the techno-capital upward spiral continues forever.” Problem: …
Like economic models:

Developing Strategic Taste
Why is it so important to write your own? Well, only by being explicit, can you understand how important your actions are, and what things need to be true about the world for your steps to make sense.

Secondly, the power law applies all the way down. I think the best way to illustrate is an example. Let’s say you’re really confident that you don’t need a theory of victory -- of course, how could something that is as broadly good as “AI verification” be bad? It’s pretty simple, it is robustly good to be able to verify properties about AI systems.
Well, I’ll tell you an account of some hypothetical people working on AI verification.
One group builds a really elaborate, steel-encased AI chip, with these fantastic security properties, but has to be custom installed on every chip, pursued through a startup to raise lots of VC funding. The other uses off-the-shelf hardware taps, and some software, and says that’s enough -- recognizing their product isn’t profitable, and being a nonprofit instead.
The second group’s actions, I claim, are much more useful because they have an eye on their “win condition:” a US-China treaty, and recognize that they do not need to produce the fancy startup, or any new technology at all. This allows them to have “taste all the way down”, and placing the full optimization pressure they are able to muster on the right part of the problem (rather than give into other pressures, like status-seeking or similar, that push them towards startups or AI labs or whatever)
You can see these people distinguish themselves as “pragmatic” (eg. pragmatic interpretability, pragmatic safety).

How do you develop your own? I like a method (that I’ve written at length about here -- much of which I will say verbatim) of “decompose and resolve.” The basic idea is simple: you can hear the lie when you say it. It works on your personal life (try saying: “My life is 100% perfect”, and then decompose: “my social life is 100% perfect” all the way down), and, also, on breaking down the problem. See the following few steps.

The thing about taste is that it requires knowing what the questions are. It is quite an obvious thing, but asking repeatedly — what do I care about? What is my big goal (make AI go well)? My big goal (ensure everyone has freedom)? And do an exercise of breaking it down from there.
If you want to figure out what you care about, think about what your goals are, and then ask why.
“I want to solve climate change.” Why do I want to do that? “Because climate change will hurt millions of people in the next few years.” Why does that matter? Because people’s happiness and flourishing is terminally valuable. That is what you care about.
“I want to earn money.” Why? Money is not a terminal value (unless you terminally value a number going up in your bank account) — it only is valuable because you can use it to buy things. “I want money for a sense of security and the ability to support my family.” Because their security and happiness is terminally valuable.

The next thing is to say the false things out loud.
Notice what objections your gut brings up to that, instinctively. Break it into the subcomponents. Eg, “Superintelligent AIs will follow human instructions”, “If technical AI alignment is solved, society will be okay”, “Everyone will benefit from AI automation”.

Continue to break down the points into smaller points until you get confused about the object-level.
Perhaps you are confused about some fact about the world (eg. will the AGI be coming soon?) or no longer at the object-level at all, but instead social reality: for example, “oh I’m actually just deferring to this person/’scientific consensus’ who believes X” or “I’m just following the precautionary principle / [some other heuristic] generally applied”.

Once you’ve done this, try your damnest to resolve your confusions about the object-level claim. Some ideas of how you could:
Doing a ton of directed reading/research
Chatting with the AIs — be careful, they tend to be good at amplifying whatever thing you subconsciously believe, and are not very good at fighting back
Speaking to a friend who has thought about this — in general, people who have just been around for longer have asked themselves the same questions, and would find it interesting to do that kind of exploration with you
Or experts in the field — I’d recommend reaching out to them cold with a specific question about their work, while doing enough prep such that it would be incredibly unlikely you could’ve figured out the answer by reading things on the internet / speaking with Claude

Now, zoom out and survey the landscape. There are at least some smart people that are trying to help — why are the things they are doing not sufficient? Usually by asking this question, you’ll realize there is maybe a structural thing going on (the bottleneck to any project happening is X funders’ risk aversion, or lack of money overall, the people aren’t that talented) or that they have missed a key strategic insight (you would be shocked at how few people actually do the steps outlined above, and reason from first principles).

And finally, write it down, and act. Write out your theory of victory. It should be a few bullet points, and all the assumptions and uncertainties. Share it with people you know! Share it with your smart friends who know how to ask questions. Share it with me (@jason.17 on Signal).

Common Traps
There are a few traps that you should avoid. Like Claude, you are a general agent. Yes, personal fit is important, and burnout is bad, but also you are more capable than you know. If you think public buy-in is important, start a movement. If conservative AI policy is, go work on that. If you think the national security establishment is, then you can reach people there too.

As AI safety becomes more established, we start to see more established status ladders, and regular paths. And don’t get me wrong, these programs are great, but be careful -- don’t turn your brain off for someone else’s agenda, or because doing the next program is cool and high-impact. They exist to serve you, and you should view them as resources, not goals.
Particularly if they are very competitive, you may be less counterfactual (ie. it would exist without you) -- do the thing that wouldn’t exist without you.

I hear many a person who has said “the portfolio approach” allows me to work on this (I don’t want to have to make a decision / leave my cushy job, so I’m going to “make a bet on long timelines”, because some part of the portfolio needs to, and I’m an unusually good comparative fit.)
Portfolios and decorrelated bets are really important, but be specific about what assumptions need to be true for your bet to make sense. Ideally, for example, you can choose to play on hard mode, where you are working in the fraction of worlds where alignment is hard, timelines are short, and warning shots are unlikely -- that’s a part of the portfolio that is neglected.

The canonical reference. Maybe you’re not Actually Trying. Even if you’re exceptional in one part of your life, this other might be a blocker. Ask yourself the question: “What would I do if I was 10x more agentic?” Also Do One Thing.
Finally, I would encourage you, stare at the hard problem. This requires courage, because it may lead you to conclude that the past 5 months of your work contributed very little value, or were totally misguided.

Stare deep into the void, and then come out again, with a plan. Good luck.
Here are all the slides (request access)
Thanks to Sophie Kim for her extensive feedback and pushing me to post this.
I remember talking with Rudolf Laine about a similar concept a few months back, where we discussed the idea that AI safety work disproportionately rewards incremental research and outlining new problems, as opposed to offering solutions. Because any solution will inevitably have flaws, and because the attack surface of the problem is so vast, it's much easier to publish work on identifying new problems than it is to present a coherent solution that tries to resolve the issue you've pointed out.
I came into the talk he was giving with a similar problem. I basically don't buy the d/acc plan, and by extension the argument L&D give for promoting proliferation in the Intelligence Curse. But d/acc not working doesn't negate the inconvenient reality of concentration of power! If you take that problem seriously, your solution still needs to get around to addressing it, as well as everything else you're worried about: controlling institutions that are hard to coup, handoff to a night watchman ASI, preventing anyone from ever building superintelligence, etc.
It's also important to present ToV's that are mutually coherent. A common example of this is:
1. Misuse of superintelligence to design superweapons is a catastrophic risk -> We should get the government to restrict the deployment/distributed development of at least the most powerful systems.
2. Concentration of power risks gradual disempowerment of the public -> We should redistribute the benefits of AI.
Each of these are individually reasonable to argue. But the problem is that most solutions to 1 will necessarily preclude 2: in order for the gov to prevent proliferation of the most powerful AIs, it needs a monopoly on violence to enforce its laws (domestically, or as part of an international coalition). But it can only maintain this monopoly on violence by proactively monopolizing the AI systems capable of violence! And if it has this monopoly, the state has the power to revoke whatever redistribution it's doing whenever it likes.
Likewise: you can't stop a country from building nukes if they already have one. The only way international atomic nonproliferation can work is if the coalition of nuclear states has, effectively, a decisive strategic advantage over their competitors. It's not like you can bomb Iran's enrichment facilities if they're already done developing a nuclear weapon---the risk of retaliation is too high.
If AI systems can cheaply/easily design new offense-dominant superweapons, then we'll end up in a similar dynamic: they'll need to be monopolized if you want the government to be able to enforce *any* restrictions on development, or else OpenAI will become the state (or worse, a regional warlord).
D/acc is, for its faults, a coherent solution to this: it would remove the need to monopolize AIs in the first place. But what if I don't think the "strong-d/acc" view that every AI-enabled offensive tactic can be resolved defense-dominant is right, and that there is at least one capability/superweapon so offense-dominant that general superintelligence itself needs to be monopolized? Then we'd still need state control, and all the problems at come with it.
To reconcile this, we'd need to figure out why monopolizing nuclear weapons worked---why every government that has nukes doesn't just point them at their citizens and neighbors without them and extract resources. Is it because coordination across the chain of command is too hard? Retaliation from other nuclear states? Gains from trade exceeding what could be taken? Poor threat credibility? Which of these restraints would ASI break? (Probably threat credibility & gains from trade). Which are useful for designing AI institutions? (Probably making the chain of command over ASI systems really big).
In other words, if I think d/acc won't work, then I need to bite the bullet on a coherent plan to get around that. We'd need to design government institutions that are difficult for one actor to take over and disempower everyone else, while still giving them the final say over superintelligence.
Over time, I've actually come to rely less and less on theories of victories. I feel I have better taste for people than I do about long causal chains that anticipate the forces of history.
My 'Theory of Victory', if it can even be called that way, is something like:
1. Scour for people you're viscerally excited by
2. Do everything you can to have them do great
3. Hold the unwavering ungrounded faith that this will be enough
I guess someone needs to have a theory of victory, but that need not be me necessarily